In this article we present a detailed description of the new AMD CPU architecture: Bulldozer. We will unveil the details of the system architecture and of the various components integrated into the chip. In today's debut four new models based on this architecture: FX-8150, FX-8120, FX-6100, FX-4100. We will see the features after having explained in detail the innovations introduced by AMD.
Overview
The Bulldozer project was started in 2006 as an architecture redesigned from scratch. Its launch was programmed to be in 2009 on 45nm SOI process, but, as we know, this project has been canceled.
It is not known if the original design had an architecture similar to the one we're going to present today: various rumors indicated the possibility of a very fast architecture, low FO4 (normalized delay of one pipeline stage) and a high number of pipeline stages, thus similar to the fatal NetBurst architecture, or even a similar architecture, if not identical, to the current Bulldozer, or both hypotheses.
What is known is that the project has maintained all the time the same name: Bulldozer.
The final Bulldozer version seems a mini-revolution in the CPU design field. After an examination of the AMD patents and published scientific papers on the topics we deduce that much of this work is merged in the development of this architecture.
The numerous delays have raised the expectations of users and the last shift, from July to October, has raised further questions about why such a choice. AMD on the other hand, had announced that it had been postponed only for a marketing choice, without any implication of a technological nature.
Today Bulldozer CPUs are presented by AMD as the first 8 core desktop CPU, and as fastest CPUs on the market, thanks to the records obtained in terms of overclocking frequencies reached, well 8429 MHz using extreme cooling.
We shall now see in detail the architecture of Bulldozer, to try to appreciate even better these statements.
System Architecture
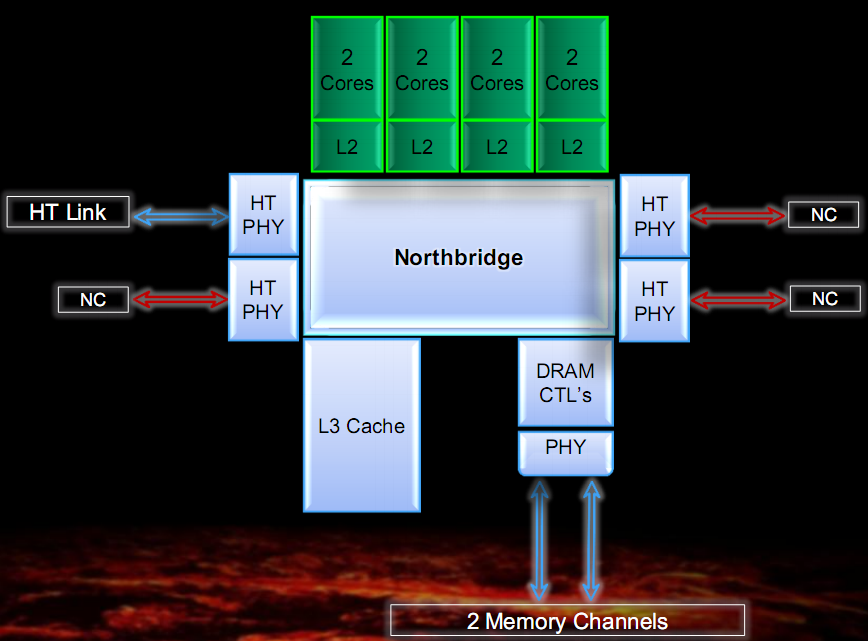
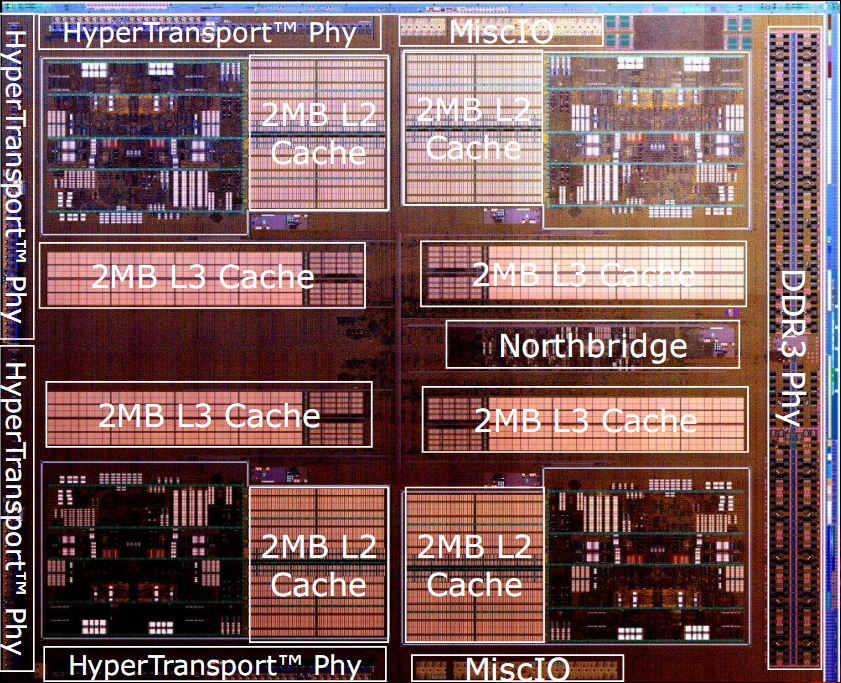

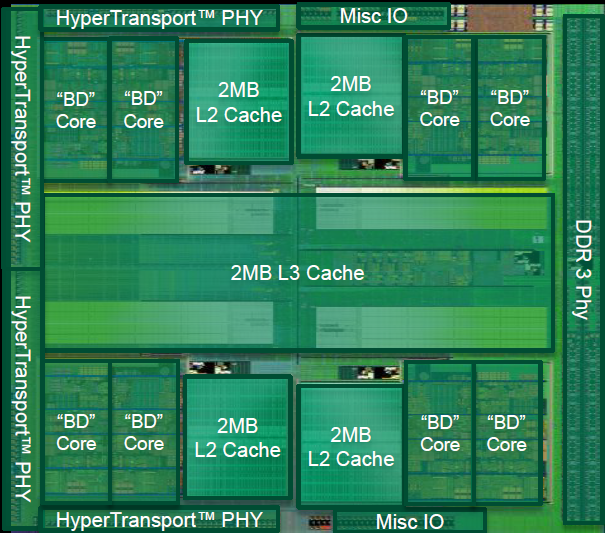
In the figure are shown a simplified block diagram and two photos of Bulldozer dices, with outlined the various components of the architecture.
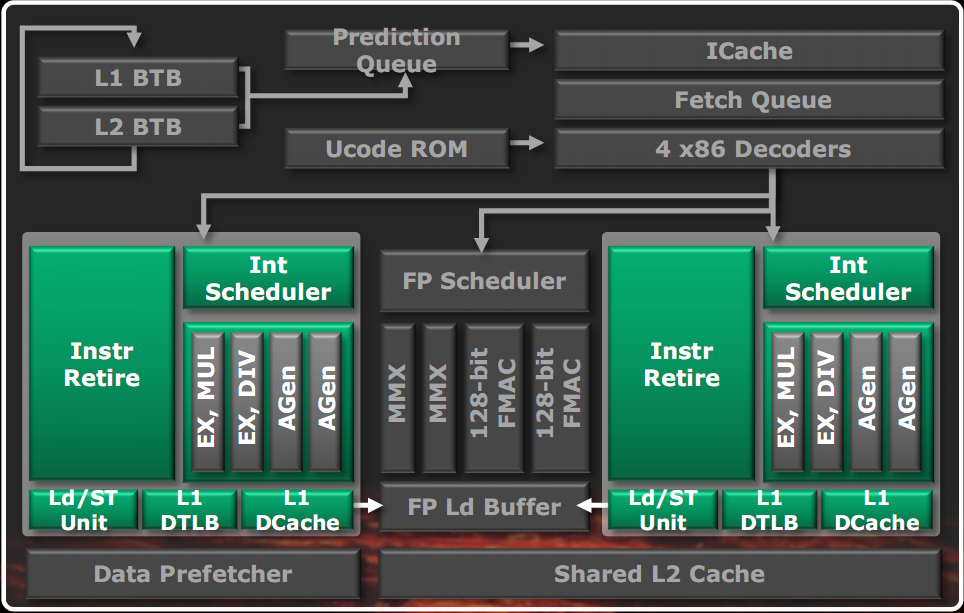
The first thing to note is that the minimum unit of processing is the so-called module, which implements two Bulldozer class core.
The chip architecture includes four modules, each consisting of two cores and 2MB of shared L2 cache, a North Bridge that manages the interconnection between all the elements of the chip, 8MB of shared L3 cache, a dual-channel DDR3 memory controller and four HyperTransport controller, of which only one active in the CPU desktop class.
The ultimate goal of AMD's designers was to maximize the performance-per-watt, taking into account also the occupied area. This was achieved in various ways. From an analysis of the literature is emerged that there is an optimal processor pipeline complexity to get the best performance per watt ratio.
Simple pipeline and with a large number of stages allow you to have high clock, but low IPC (instructions per clock). Consumption explodes with clock increase and then you can not increase too much this parameter, reaching an impassable limit on performance.
Complex pipeline, with few stages are slower, but have high IPC, balancing the lower clock. Having a large number of transistors, occupy more chip area and consume more energy in leakage (leakage currents), due to the large number of transistors. This also translates into an additional limitation to the maximum achievable clock.
The optimal condition is halfway between these two extremes and was established by several theoretical studies in the literature. An index of the pipeline complexity is the FO4, which indicates how much is the normalized delay of one pipeline stage. The higher this number, the more complex (and slow) is the stage of the pipeline, and hopefully less pipeline stages are needed to implement a given architecture.
It has been shown that a 17-FO4 is the optimum for a CPU built on modern production processes. This value is that used for the Bulldozer pipeline. By way of comparison, the K10 has a FO4 of about 22, while the Sandy Bridge has about 24 and that of a Pentium 4, about 13. For what said before, it's clear that K10 and Sandy Bridge are complex pipeline architectures and low clock while the Pentium 4 is a simple pipeline architecture with high clock.
Given the complexity of the optimal pipeline now the problem is to implement the CPU with a minimum number of transistors.
One of the things that was done is the sharing of all underutilized units. This is why the birth of the module.


In the left figure we can see the classic implementation of a dual core CPU, with duplication of most of the components.
In the right figure is shown a block diagram of a Bulldozer module.
Units that are not used in full for most of the time were shared between two cores, so you may also make them more powerful than the case of separate units, because now the transistors budget is divided between two core and then you can use more for a single unit.
As shown in the figure, the shared units are the fetch unit, the decode unit, the floating point unit and the L2 cache. The L1 data caches and integer units have been separated since it was established that they are the most commonly used units of a core. This approach allows two threads to run at an average speed of 80% compared to the case of separate cores in an area of only 12% more than a single core (not counting the L3 cache, the North bridge controller and the RAM).
Lowering the number of transistors, lowers the leakage and thus allows higher clock at the same TDP. But to have even higher clock we must have a very effective energy saving.
The strategies implemented in Bulldozers are: the extensive clock gating of logic networks throughout the die, i.e. off the clock for the units not used in a given time; extensive power gating logic circuits, i.e. off the power supply for units not used at any given moment; C6 off state implementation for the modules or the entire package, with rings around the drive transistors; P-state for energy savings or turbo-core, to have at any time the optimal consumption in function of load, a feature allowed by the APM module (advanced power management), which measures instantaneously the consumption of the chip and determines the optimal P-state; the energy savings of the RAM modules and finally the C1E power state, in which an idle core consumes as little as possible without being turned off completely.
Last implemented feature in Bulldozer is Turbo Core.

The turbo core uses the APM unit to determine how long the CPU can be in the best possible state of turbo without exceeding the maximum consumption limit. When all the cores are used, there is almost always some units not used in the chip. The APM unit calculates the TDP budget and the turbo core unit, using a dithering algorithm, calculates how much time the CPU can be in a state of turbo without exceeding the TDP. If you have used half or less of the core, the usable turbo state provides even higher clock.
We come now to a list of the main features of the various units of a Bulldozer module.
Fetch and Decode Unit
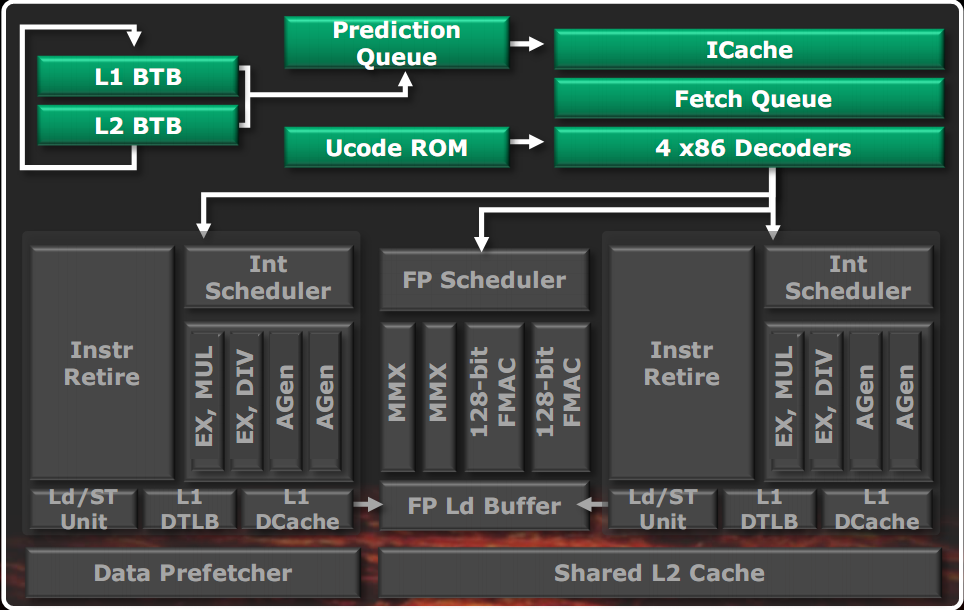
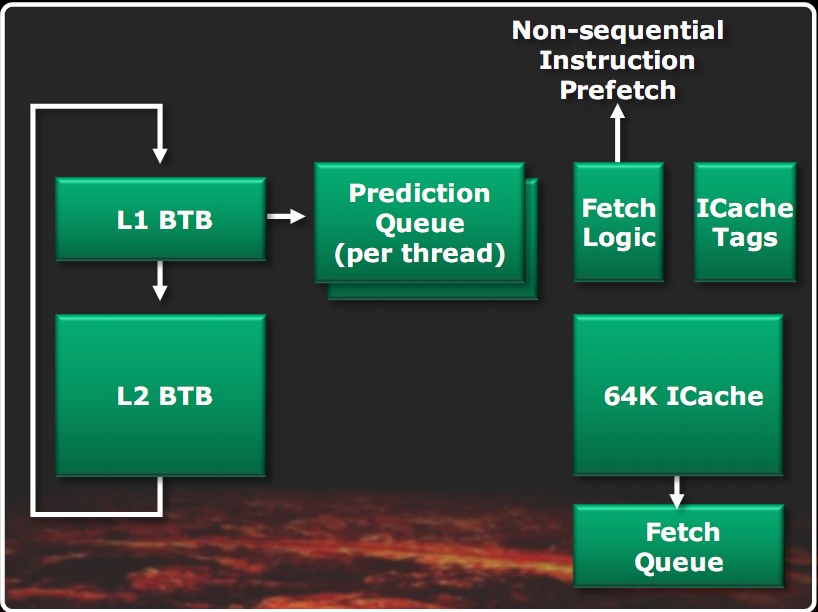
In the figure shown on the left we see the front end of a Bulldozer module. On the right is shown in more detail the branch prediction diagram.
Compared to classical architecture, we see the branch prediction unit decoupled from the real fetch unit: this allows you to make branch predictions in parallel and independently of the instruction fetch. Prefetching is driven by the branch prediction, to find in cache the necessary instructions as soon as possible. The instruction cache is 64KB two-way. The instruction fetch is 32 bytes at a time. The instruction TLB are two levels, with an first level of 72 elements fully associative, shared between all page measures and a the second level of 512-item 4-way, with only the 4KB pages. The decoding unit is also able to make the branch fusion. The decoders are 4 and can generate 4 macros instructions per clock, alternately to the two threads.
The branch predictor is double and works independently for the two threads. The prefetch requests are done in parallel to the L2 cache and memory, whenever missing in the L1 cache. The predictor, in addition to being divided by thread, is also divided into two levels. The first level is faster but less accurate, based also on an L1 cache BTB (Branch Target Buffer, i.e. a cache that stores the IP addresses of jumps performed in the past, that the predictor returns as a prediction, if the jump is predicted as taken) the smallest (of 512 elements). His prediction is filed timely in the queue and is started in parallel with the second level prediction, which uses, among other things, a much larger L2 BTB cache (5120 elements). When the second level prediction is ready, if the result of the first level prediction has not been used yet, it is overwritten by the second level, presumably more accurate. This allows you to combine the advantages of a fast predictor, and an accurate one. The prediction of the procedure returns is carried out by a separate unit.
Integer unit
In figure you can see a simplified diagram of the two integer pipelines contained in a Bulldozer module.
Each of the two cores has a unified instruction scheduler, able to carry out the instructions as soon as the necessary data and execution units are ready. The execution units are 4, two of which are capable of performing address calculation instructions and simple arithmetic logic instructions (Agen), one can perform complex arithmetic instructions, as well as multiplications (Ex MUL) and one can perform complex arithmetic instructions, as well as divisions (Ex-DIV). Each unit is equipped with a 16KB L1 data cache with write-through writing policy and mostly exclusive with respect to the L2 cache, a TLB data cache of 32 pages, fully associative and a load/store unit, completely out of order, capable of performing two 128-bit reads and a 128-bit write per cycle, with a queue of 40 positions for reads and 24 for writes.
Floating Point Unit
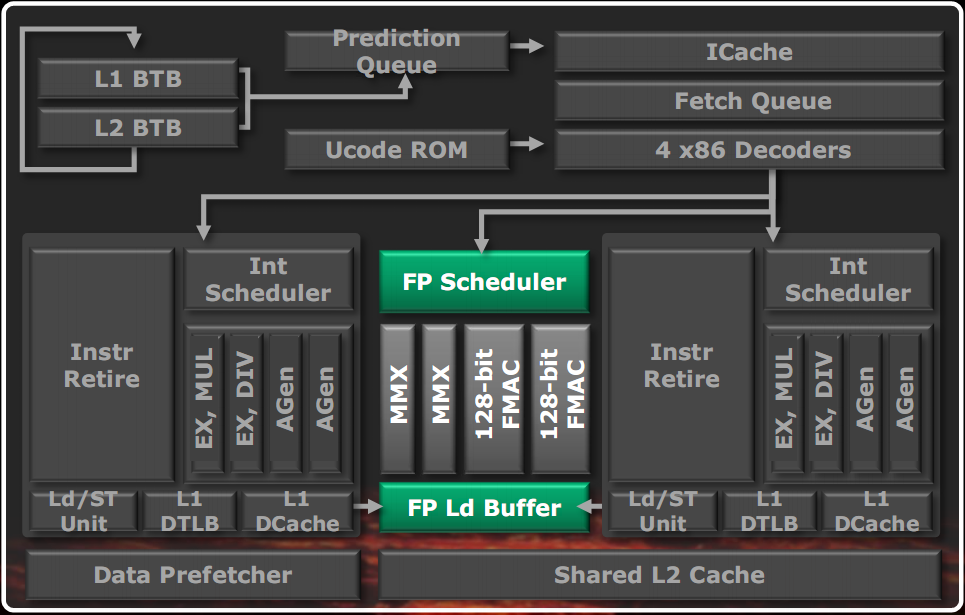
In the figure there is a simplified diagram of the floating point unit (FP) contained in a Bulldozer module. It is organized as an external coprocessor, which receives instructions to run from the outside and reports the results back to the requesting core. The connection between FP units and integer core is bidirectional: it receives instructions and data from the integer cores, reports a completion signal back (the retire of the instructions is still run by the integer core), is connected with two 64-bit buses to the integer cores for the execution of convert instructions from integers to FP numbers and vice versa and is connected to the load and store units of the two integer cores to perform memory operations.
It consists of a unified scheduler, which can receive up to 4 instructions per clock cycle alternating the two integer cores and send running up to 4 instructions per clock cycle, even mixing those of both threads, at 80/128 bits. The scheduler is fully data-driven: when the data needed and the execution units are free, the instruction is executed, being careful to be fair between the two threads.
The execution units are 4 and are able to perform 2 FP FMAC operations (Fused Multiply Accumulate, i.e. a multiplication and a fused accumulation, namely a calculation of the type d = a + b * c) and 2 IMAC operations (Integer Fused Multiply Accumulate, such as the FMAC, but on integers) per cycle. The x87 operations are managed by FMAC. The divisions and square roots are always handled by FMAC. Some special operations are managed by IMAC, such as permute, the memory one are handled by the two IMAC pipeline and registers movements are mostly carried out on the fly without taking execution units. Thanks to a patent filed by AMD, FMAC and IMAC units are able to perform even simple additions or multiplications with the same circuit, without unnecessary duplication. The units are 128 bits and can be joined together to perform 256-bit operations.
L2 cache and system memory
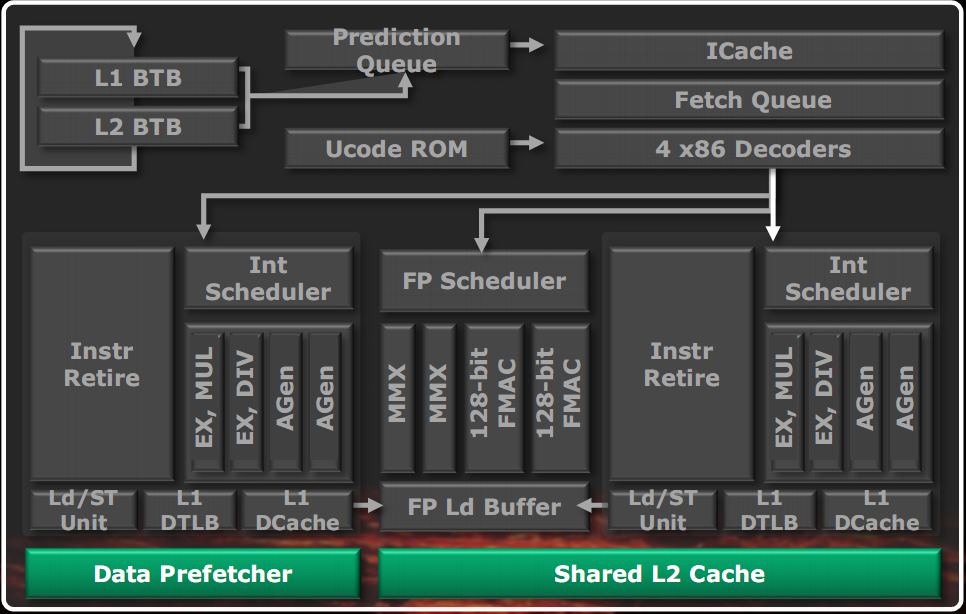
The L2 cache is equal to 2MB organized in 16-way. The second-level TLB is 1024 pages 8-way and serves both data and instruction caches. The L2 prefetchers are multiple and can have up to 23 outstanding transactions to memory.
The L3 cache is also 8MB organized in 4 banks of 2MB and is shared between the 4 modules. It's a victim cache, which contains the data that must be removed from the L2 cache of the various modules, to make room for new data. It works the same frequency as the North Bridge, which also operates four HyperTransport controller and a dual channel DDR3 memory controller that supports up to 4 memory modules and memory up to 1866 MHz.
Supported instructions
The instructions supported by Bulldozer are SSE up to 4.1 and 4.2 included, the 256-bit register AVX, instructions for the AES encryption acceleration, and 4-operand nondestructive FMA instructions (XOP instruction set).
CPU at debut
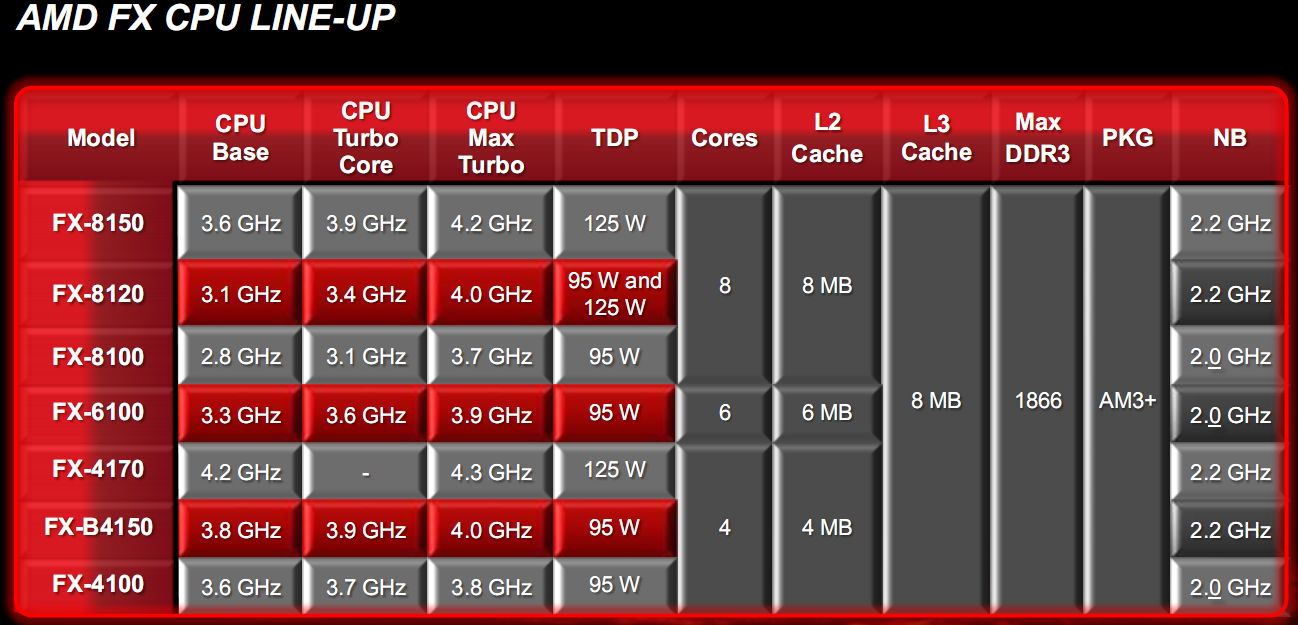
In figure one can see the overview of the various Bulldozer CPUs available from October 12, 2011. As you can see there are 4 models in the 8xxx FX series at 125W and 95W of 8-core (the FX 8150, FX 8120 and FX 8100), a 6-core model of 6xxx FX series (FX 6100) and three 4-core models 4xxx FX series (models FX 4170, FX B4150 and FX 4100), with the frequency record for the desktop CPU as the CPU FX 4170 has 4.2GHz, which will be introduced later.

In this figure we can see the list of available CPUs to launch from October 12, 2011, together with suggested retail prices. As you can see we have two CPU 8xxx FX series of 125W (FX 8150 and FX 8120, whose 95W version will be introduced later) at a suggested retail price of € 239/249 and 199/209 €, respectively, and two models of 4 and 6-core of 95W (FX 4100 and FX 6100), with a suggested retail price of € 109/119 and 149/159 € respectively. Unfortunately the prices in Euros are not as interesting as those in dollars, with the top of the line CPU from AMD that is positioned at a price slightly less than the Intel Core i7-2600K, which at present amounts to around € 260/270. From the point of view of functionality the FX-8120 CPU, is still the same of the FX-8150, except for a lower clock frequency. You need to evaluate the overclocking potential of these CPUs to understand the true potential of the Bulldozer CPU.
In the coming days we will publish a detailed analysis of the performance, which will allow you to choose the CPU that best suits your needs.
Preliminary Bench
The FX line of AMD is characterized, among other things, for operating frequencies, the number of cores and the fact that you have unlocked multipliers:

The preliminary bench which are shown below, are made by AMD and reported excellent performance for gaming and comparable performance to similarly priced Intel processors in the other benchmarks.
The tests are based on comparisons between AMD FX-8150 and Phenom X6 CPUs and INTEL CPUs from time to time specified. For consistency they chose to have 8GB of DDR3 1333 (even if it penalizes a little AMD FX 8150 CPUs, since they support memory up to 1866 MHz) and Windows 7 64-bit.
We begin with a comparison in situations of extreme resolutions with EyeFinity configuration and crossfire setup of HD6970 GPU, compared to a Core i5 2500K:
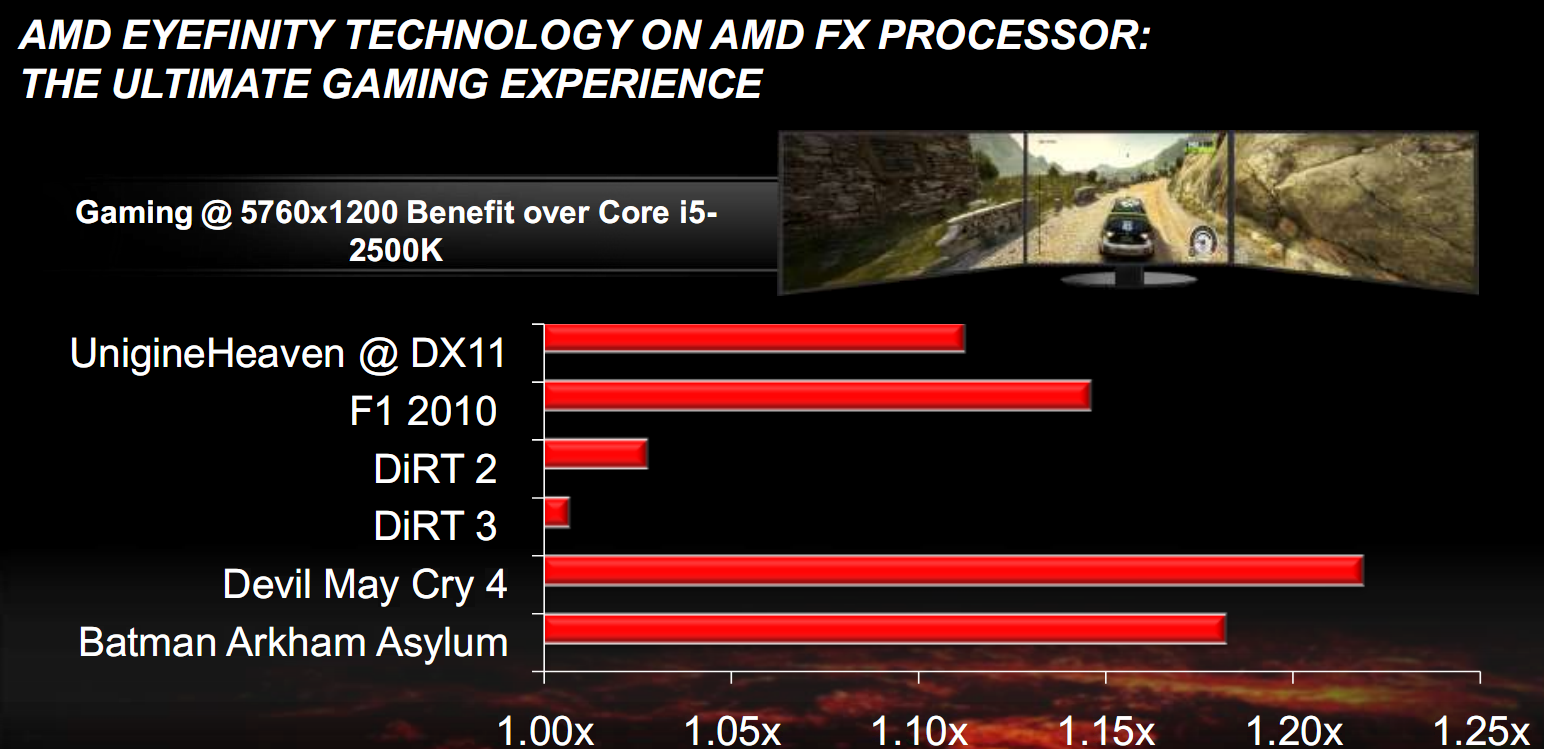
As you can see, the benefits are obvious and range from a low of 1% to a maximum of 22%.
The next test concerns Battlefield 3, comparing the AMD FX-8150, Phenom X6 and Intel 2500K, with a single HD 6950.
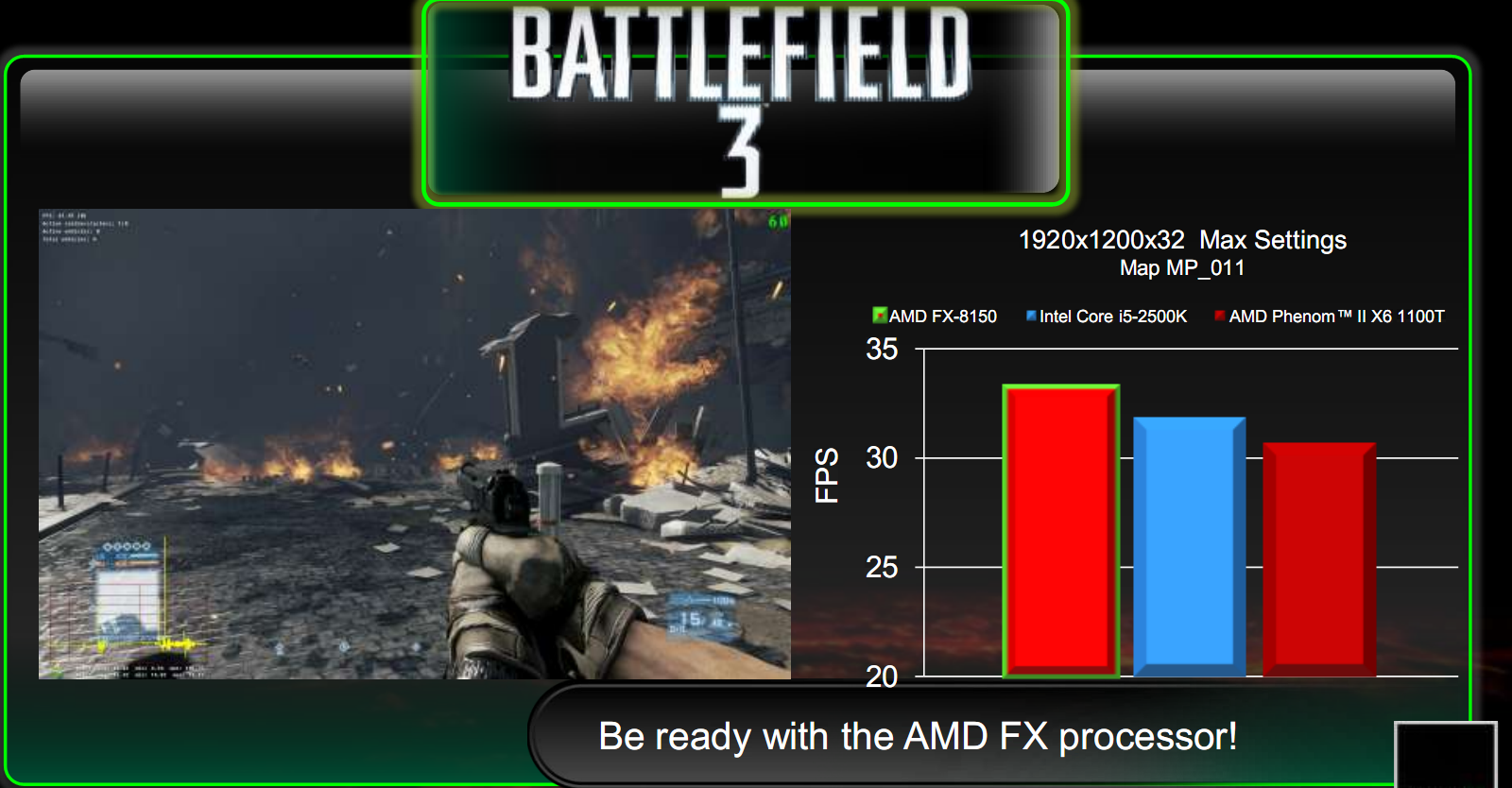
The improvement of AMD from one generation to another is a few FPS, however, enough to surpass even the Intel solution.
The last test gaming shows an extreme case: the use of top of the range CPU Intel Core i7-980X is not economically viable. To play most games with performance aligned or higher (with two exceptions), you need just an AMD FX 8150, saving, also $800:
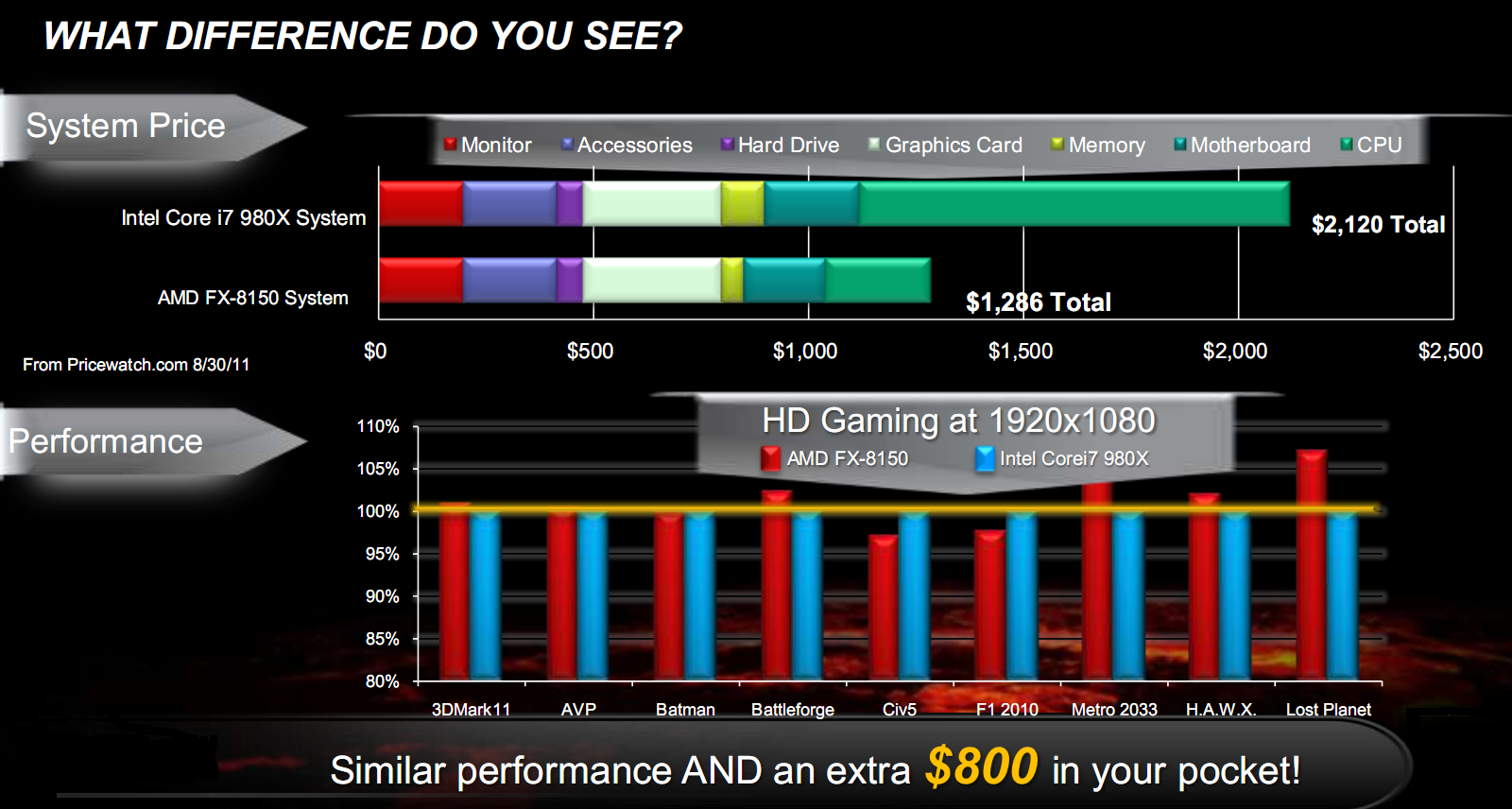
Unfortunately lacking in this case the comparison with Sandy Bridge, direct competitor of Bulldozer.
Turning to the general purpose multi-threaded applications, the FX 8150 is still above 2500K ( with respect to which was normalized the graph) and generally aligned to 2600K, as shown in the following chart:

This slide is curiously different from what appeared a few days ago by rumors, with the values of FX and AMD 2600K exactly reversed. Even from these tests is nevertheless clear that the 8-core Bulldozer does not have performance comparable to a traditional 8-core, but show generally comparable performances to an Intel quad core with Hyper Threading.
Finally, the performance of the FX 8150 in Cinebench 11.5 64-bit at default (3.6GHz) and with an overclock to 4.8GHz:

This result indicates a good scalability in frequency, given by a performance increase of 31% compared with an increase of 33% of the clock, but the performance may be higher than that using memory of 1866 MHz even at default and finally you could get more performance in overclocking, increasing the frequency of the North Bridge and RAM. The result in absolute terms is not very encouraging for a CPU defined as having 8 cores.
Conclusions and considerations
AMD is back with a new architecture optimized for better performance, area and consumption ratio, hence the cost of production. Every single item was chosen to be the best compromise. Reducing consumption can rise clock frequencies and allows for higher turbo.
AMD's approach used to resource sharing is called Clustered Multi Thread (CMT). Unlike Intel's SMT, this approach does not sacrifice too much performance in multi-threaded, when two threads are competing for resources in the module, since only the underutilized units were actually shared and additionally enhanced, because they took the place of two units.
AMD is finally up with the Intel instruction set and actually implements its own set of instructions, the XOP and FMA4, which implement the 4-way FMA (4-way Fused Multiply Accumulate, i.e. the calculation of the formula d = a + b * c, contrary to the FMA 3, which calculates the formula a = a + b * c, destroying a register and requiring a rescue, should serve its content), which delivers great advantages in optimized code:

Finally, the turbo core gives tangible benefits on the performance, trying to exploit the untapped potential of TDP by the various software:

The Bulldozer die in 315 square mm includes 8 cores for a total of 2 billion transistors, can operate at a frequency of over 4 GHz staying in a TDP of 125W. This is certainly an excellent result if we consider the past architectures of both Intel and AMD.
AMD has produced the first 8-core x86 CPUs as it defines it, though that does not have the performance you expect from a real eight-core as the sharing of parts of cores, however, has its disadvantages. From the standpoint of performance, they are approximately aligned with those of an Intel CPU with 4 cores and capable of handling 8 threads. We would like to say this especially for inexperienced users who may mistakenly take the trivial association "CPU with more cores = more powerful CPU."
With this CPU, AMD also has a new record of extreme overclocking frequency, equal to 8429MHz in liquid helium. These two records are a good omen for the success of the CPU, confirmed by preliminary tests carried out by AMD. This certainly is not enough to define the FX-8150 the fastest CPU on the market, at least not in absolute terms.
In the coming days we will publish a detailed performance analysis of this new architecture from AMD, with extensive tests carried out by our staff, as well as a deeper analysis of the architecture. Stay tuned!
Marco Comerci